Workflows: A full-fledged orchestration tool in Databricks platform


Share

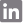


Introduction:
Databricks workflows is a component in Databricks platform to orchestrate the data processing, analytics, machine learning and AI applications. Workflows have evolved so much that we don’t require a third-party external orchestration tool. Depending on external tools for orchestration adds complexity in managing and monitoring capabilities.
Basic features like scheduling, managing dependency, git integration to advance level capabilities like retires, duration threshold, repair and conditional tasks are available in Databricks workflows.
A task is a unit of execution in the workflow. Workflow supports a wide range of tasks like notebooks, SQL and Spark scripts, Delta Live Tables pipelines, Databricks SQL queries, and dbt jobs. As it supports all varieties of tasks, a workflow can be sufficient to orchestrate an end-to-end pipeline for a subject area.
Databricks job:
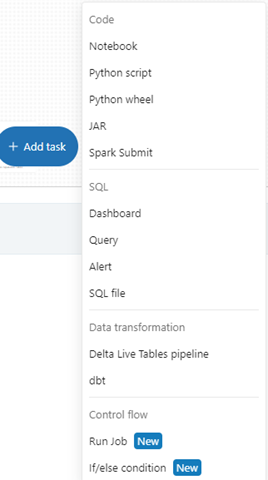
A job in Databricks workflow is to group multiple tasks into one for better management and reusability. For each job we can set different types and sizes of compute clusters, notifications and triggers based on requirement. Databricks clusters add reliability and scalability to jobs. Databricks jobs automatically generate the lineage providing upstream and downstream tables for that job.
Jobs can be managed from Databricks UI or Databricks REST API. REST API opens a whole set of capabilities to easily integrate with any outside tool.
For example, a data engineering team can create a job for ETL, a data science team can create a job for their ML models and finally, an analytics team can create a dashboard refresh. All these jobs can be tied together into a single parent workflow, reducing complexity and better management.
A company dashboard or report can only be built using data that was processed by different teams in an organization. So, each team’s job is dependent on the preceding jobs. Since all jobs are dependent on one another, we can either set dependence on preceding jobs or schedule jobs at fixed times or set file-based triggers that can be set on external storage services like ADLS.
Notable features:
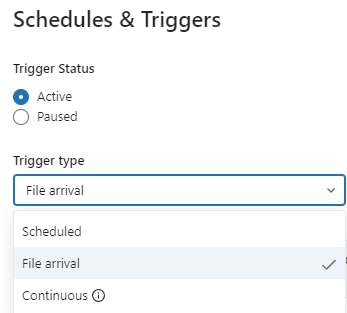
The Retry Policy, as shown in the picture below, allows you to set the maximum number of retries and a defined interval between the attempts.

Repair job is a very useful feature for developers while testing a job or for production failures. When we repair a job, it doesn’t run from the beginning, it will re-trigger the pipeline from the failed activity. In contrast, the Re-run feature will run the pipeline from the beginning of the task.
Provides a graphical interface matrix view to monitor the workflow at task level.
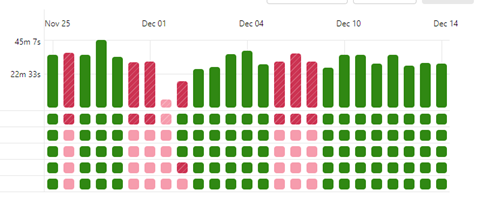
Databricks workflows are also integrated with Git. Using Databricks REST API we can streamline the deployment process of the workflows by a CI/CD pipeline.
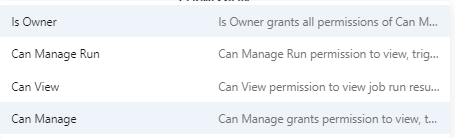
Like any other component in Databricks, workflows also come with access control. There are four types of access levels available.
Databricks workflow integrates with popular tools like Azure Data Factory, Apache Airflow, dbt and Five Tran.
Notifications:
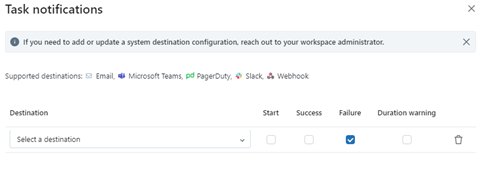
Orchestration tool cannot be complete without notifications/alerts, data bricks workflows provide various types of notifications. Email based notifications which sends email containing information of start time, run duration, status of the job. Other supported integrations are Microsoft Teams, Slack, PagerDuty and a custom webhook.
Control flow:
Control flow mainly contains two functions.
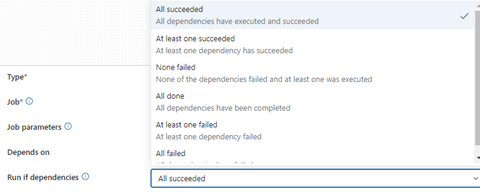
- a) Run Job, triggers a task based on preceding task status. Run if dependencies contain 6 different types of options.
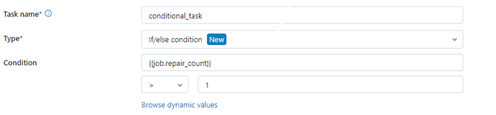
- b) If/else condition triggers a task based on the job parameters or dynamic values.
To summarize, Databricks workflows evolved as an alternative to the other external orchestration tools. Advanced features and capabilities make it a no-brainer to opt for Databricks workflow over external tools for managing Databricks pipelines.
If you wish to know more about our data engineering services, drop a line here.
Ready to get started?
From global engineering and IT departments to solo data analysts, DataTheta has solutions for every team.